Perl 6 rules
Perl 6 rules are the regular expression, pattern matching and general-purpose parsing facility of Perl 6, and are a core part of the language. Since Perl's pattern-matching constructs have exceeded the capabilities of formal regular expressions for some time, Perl 6 documentation refers to them exclusively as regexes, distancing the term from the formal definition.
Perl 6 provides a superset of Perl 5 features with respect to regexes, folding them into a larger framework called rules, which provide the capabilities of a parsing expression grammar, as well as acting as a closure with respect to their lexical scope.[1] Rules are introduced with the rule keyword, which has a usage quite similar to subroutine definition. Anonymous rules can be introduced with the regex (or rx) keyword, or simply be used inline as regexps were in Perl 5 via the m (matching) or s (substitution) operators.
Contents |
History
In Apocalypse 5, a document outlining the preliminary design decisions for Perl 6 pattern matching, Larry Wall enumerated 20 problems with "current regex culture". Among these were that Perl's regexes were "too compact and 'cute'", had "too much reliance on too few metacharacters", "little support for named captures", "little support for grammars", and "poor integration with [the] 'real' language".[2]
Between late 2004 and mid-2005, a compiler for Perl 6 style rules was developed for the Parrot virtual machine called Parrot Grammar Engine (PGE), which was later re-named to the more generic, Parser Grammar Engine. PGE is a combination of runtime and compiler for Perl 6 style grammars that allows any parrot-based compiler to use these tools for parsing, and also to provide rules to their runtimes.
Among other Perl 6 features, support for named captures was added to Perl 5.10 in 2007 [3].
Changes from Perl 5
There are only six unchanged features from Perl 5's regexes:
- Literals: word characters (letters, numbers and underscore) matched literally
- Capturing:
(...) - Alternatives:
| - Backslash escape:
\ - Repetition quantifiers:
*,+, and?, but not{m,n} - Minimal matching suffix:
*?,+?,??
A few of the most powerful additions include:
- The ability to reference rules using
<rulename>to build up entire grammars. - A handful of commit operators that allow the programmer to control backtracking during matching.
The following changes greatly improve the readability of regexes
- Simplified non-capturing groups:
[...], which are the same as Perl 5's:(?:...) - Simplified code assertions:
<?{...}> - Extended regex formatting (Perl 5's
/x) is now the default.
Implicit changes
Some of the features of Perl 5 regular expressions become more powerful in Perl 6 because of their ability to encapsulate the expanded features of Perl 6 rules. For example, in Perl 5, there were positive and negative lookahead operators (?=...) and (?!...). In Perl 6 these same features exist, but are called <before ...> and <!before ...>.
However, because before can encapsulate arbitrary rules, it can be used to express lookahead as a syntactic predicate for a grammar. For example, the following parsing expression grammar describes the classic non-context-free language 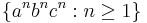 :
:
S ← &(A !b) a+ B A ← a A? b B ← b B? c
In Perl 6 rules that would be:
rule S { <before <A> <!before b>> a+ <B> }
rule A { a <A>? b }
rule B { b <B>? c }
Of course, given the ability to mix rules and regular code, that can be simplified even further:
rule S { (a+) (b+) (c+) <{$0.elems == $1.elems == $2.elems}> }
However, this makes use of assertions, which is a subtly different concept in Perl 6 rules but more substantially different in parsing theory, making this a semantic rather than syntactic predicate. The most important difference in practice is performance. There is no way for the rule engine to know what conditions the assertion may match, so no optimization of this process can be made.
Integration with Perl
In many languages, regular expressions are entered as strings, which are then passed to library routines that parse and compile them into an internal state. In Perl 5, regular expressions shared some of the lexical analysis with Perl's scanner. This simplified many aspects of regular expression usage, though it added a great deal of complexity to the scanner. In Perl 6, rules are part of the grammar of the language. No separate parser exists for rules, as it did in Perl 5. This means that code, embedded in rules, is parsed at the same time as the rule itself and its surrounding code. For example, it is possible to nest rules and code without re-invoking the parser:
rule ab {
(a.) # match "a" followed by any character
# Then check to see if that character was "b"
# If so, print a message.
{ $0 ~~ /b {say "found the b"}/ }
}
The above is a single block of Perl 6 code that contains an outer rule definition, an inner block of assertion code, and inside of that a regex that contains one more level of assertion.
Implementation
Keywords
There are several keywords used in conjunction with Perl 6 rules:
- regex
- A named or anonymous regex that ignores whitespace within the regex by default.
- token
- A named or anonymous regex that implies the
:ratchetmodifier. - rule
- A named or anonymous regex that implies the
:ratchetand:sigspacemodifiers. - rx
- An anonymous regex that takes arbitrary delimiters such as
//where regex only takes braces. - m
- An operator form of anonymous regex that performs matches with arbitrary delimiters.
- mm
- Shorthand for m with the
:sigspacemodifier. - s
- An operator form of anonymous regex that performs substitution with arbitrary delimiters.
- ss
- Shorthand for s with the
:sigspacemodifier. /.../- Simply placing a regex between slashes is shorthand for
m/.../.
Here is an example of typical use:
token word { \w+ }
rule phrase { <word> [ \, <word> ]* \. }
if $string ~~ / <phrase> \n / {
...
}
Modifiers
Modifiers may be placed after any of the regex keywords, and before the delimiter. If a regex is named, the modifier comes after the name. Modifiers control the way regexes are parsed and how they behave. They are always introduced with a leading : character.
Some of the more important modifiers include:
:ior:ignorecase– Perform matching without respect to case.:gor:global– Perform the match more than once on a given target string.:sor:sigspace– Replace whitespace in the regex with a whitespace-matching rule, rather than simply ignoring it.:Perl5– Treat the regex as a Perl 5 regular expression.:ratchet– Never perform backtracking in the rule.
For example:
regex addition :ratchet :sigspace { <term> \+ <expr> }
Grammars
A grammar may be defined using the grammar operator. A grammar is essentially just a namespace for rules:
grammar Str::SprintfFormat {
regex format_token { \%: <index>? <precision>? <modifier>? <directive> }
token index { \d+ \$ }
token precision { <flags>? <vector>? <precision_count> }
token flags { <[\ +0\#\-]>+ }
token precision_count { [ <[1-9]>\d* | \* ]? [ \. [ \d* | \* ] ]? }
token vector { \*? v }
token modifier { ll | <[lhmVqL]> }
token directive { <[\%csduoxefgXEGbpniDUOF]> }
}
This is the grammar used to define Perl's sprintf string formatting notation.
Outside of this namespace, you could use these rules like so:
if / <Str::SprintfFormat::format_token> / { ... }
A rule used in this way is actually identical to the invocation of a subroutine with the extra semantics and side-effects of pattern matching (e.g., rule invocations can be backtracked).
Examples
Here are some example rules in Perl 6:
rx { a [ b | c ] ( d | e ) f : g }
rx { ( ab* ) <{ $1.size % 2 == 0 }> }
That last is identical to:
rx { ( ab[bb]* ) }
References
- ^ Wall, Larry (June 24, 2002). "Synopsis 5: Regexes and Rules". http://dev.perl.org/perl6/doc/design/syn/S05.html.
- ^ Wall, Larry (June 4, 2002). "Apocalypse 5: Pattern Matching". http://dev.perl.org/perl6/doc/design/apo/A05.html.
- ^ Perl 5.10 now available - Perl Buzz
External links
- Synopsis 05 - The standards document covering Perl 6 regexes and rules.
- Perl 6 Regex FAQ - Answers a range of questions about Perl 6 regexes.
- Perl 6 Regex Introduction - Gentle introduction to Perl 6 regexes.